[:es]Existe una demanda creciente de infraestructuras de alta disponibilidad, esto debido a que cada vez más empresas llevan cargas de trabajo relevantes, además de depender de servicios en la nube para procesos críticos en sus empresas. En la presente entrada se buscará dar una introducción al diseño de una arquitectura de alta disponibilidad sobre uno de los proveedores más conocidos alrededor del mundo: Amazon Web Services.
Relacionado: [:es][Webinar] Arquitectura de microservicios con Kubernetes en Amazon EKS[:]
Introducción
Todo lo que usamos en la vida cotidiana tiene presencia en Internet de una forma u otra, ya sean Redes socio digitales como Facebook, Twitter, Quora, etcétera o tiendas como Amazon o Mercadolibre.
Todos estos sitios web nos conectan con uno u otro que utiliza los mismos servicios. Con una creciente demanda de infraestructuras fiables y de alto rendimiento diseñadas para dar servicio a sistemas críticos, los términos escalabilidad y alta disponibilidad no podrían ser más populares que en la actualidad. Si bien el manejo de una mayor carga del sistema es una preocupación común, la reducción del tiempo de inactividad y la eliminación de los puntos de fallo son igualmente importantes. La alta disponibilidad es una cualidad del diseño de la infraestructura a escala que responde a estas consideraciones.
¿Qué es alta disponibilidad?
La disponibilidad, en términos informáticos, se utiliza para describir el período de tiempo en el que un servicio está disponible para su uso, así como el tiempo que necesita un sistema para responder a una solicitud realizada por un usuario. Alta disponibilidad es una cualidad de un sistema o de un dispositivo que garantiza alto rendimiento operativo durante un período de tiempo determinado. La disponibilidad se mide en porcentaje (%) de modo que cuando un sistema o un componente da el 100% de disponibilidad significa que este sistema nunca falla. Por ejemplo, un sistema que garantiza el 99% de la disponibilidad durante un período de un año, significa que podría tener un tiempo de inactividad del 1%, es decir, 3.65 días de inactividad en un año.
Entonces, si un servicio como un sitio de comercio electrónico como Amazon dejase de funcionar durante tan sólo 3 días al año, significaría una pérdida de millones de dólares, además de la pérdida de confianza de parte de los clientes.
Para superar esta situación, un arquitecto que diseña la infraestructura de los sitios o aplicaciones, se asegura de que haya un sistema geo redundante que puede ayudar en caso de una interrupción del servicio en el sistema principal.
El siguiente diagrama se muestra un servidor LAMP de alta disponibilidad (Linux, Apache, Mysql y PHP) implementado usando Amazon Web Services. En caso de que no estés familiarizado con AWS, más adelante encontrarás pequeña referencia de cada componente y su uso.
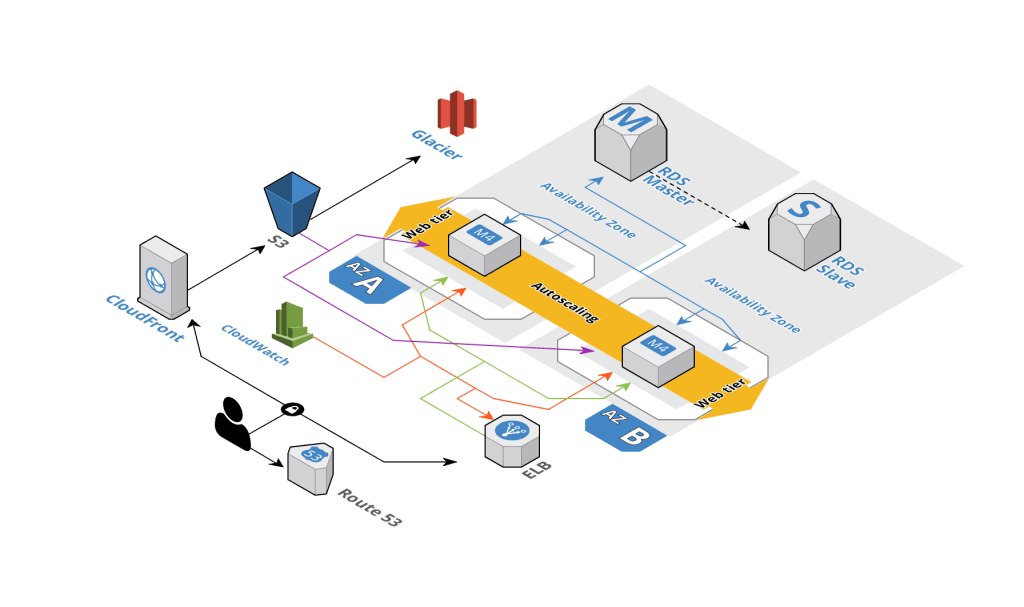
Como se puede apreciar en el diagrama, hay dos zonas de disponibilidad: A y B, cada una de ellas contiene una capa de servidor web (Web tier) y un RDS, en el caso de las capas web, contienen la aplicación PHP en sí y está replicada en las dos zonas, mientras que los RDS, uno de ellos es la base de datos primaria (Master) y en la zona B se encuentra la base de datos secundaria (slave) que es una réplica de la primaria que se mantiene en latencia, es decir que está en reposo hasta que la base de datos primaria comienza a saturarse. Frente a las dos zonas se encuentra un balanceador de carga.
Algo más a notar es que las capas de servidor web, se encuentran en modo de autoescalabilidad, es decir que en cuanto el tráfico y las peticiones se vuelvan más demandantes, se crearán máquinas nuevas que contengan la misma aplicación y las peticiones se distribuirán a las nuevas instancias creadas.
Más adelante se explorarán más arquitecturas de éste tipo, que contemplan otros escenarios similares.
Los servicios que proporcionan infraestructura básica, como Amazon Elastic Compute Cloud (EC2) y Amazon Elastic Block Store (EBS), cuentan con características específicas, como zonas de disponibilidad, direcciones IP elásticas e instantáneas (snapshots o copias parciales de los datos) que un sistema tolerante a fallos y de alta disponibilidad debe aprovechar y utilizar correctamente. El simple hecho de trasladar un sistema a la nube no lo hace tolerante a las fallas ni altamente disponible.
Referencia y glosario breve de los servicios de AWS vistos en esta publicación.
AWS – Amazon Web Services
VPC – Virtual Private Cloud, VPC es una herramienta mediante la cual puedes diseñar nubes privadas separadas dentro de una región AWS.
Región – Las regiones de AWS son ubicaciones geográficas desde las que operan los centros de datos de AWS, estas ubicaciones pueden utilizarse para diseñar recursos públicos o privados utilizando los servicios de AWS.
AZ – Las zonas de disponibilidad (AZ, Availability Zones) son lugares geográficos distintos que están diseñados para ser aislados de fallas en otras zonas. Al colocar instancias de Amazon EC2 en varias zonas de disponibilidad, una aplicación puede protegerse de fallos en una sola ubicación. En algunos casos es importante ejecutar varias aplicaciones independientes en más de una zona de disponibilidad, ya sea en la misma región o en otra región, de modo que si una zona falla, la aplicación en la otra zona puede continuar ejecutándose. Al diseñar un sistema de este tipo, se requerirá de una buena comprensión de las dependencias de zona.
Route 53 – Amazon Route 53 (Route 53) es un sistema de nombres de dominio (DNS) escalable y altamente disponible. Forma parte de la plataforma de computación en nube de AWS. El nombre es una referencia al puerto TCP o UDP 53, donde se dirigen las peticiones del servidor DNS.
ELB – El servicio de Balanceo de carga elástico (Elastic Load Balancing) se encarga de distribuir el tráfico entrante a través de múltiples recursos para que un recurso no se inunde con todo el tráfico. El balanceo de carga es una manera efectiva de aumentar la disponibilidad de un sistema. Las instancias que fallan pueden ser reemplazadas sin problemas detrás del balanceador de carga mientras que otras instancias continúan operando. El Balanceo de Carga Elástico puede ser usado para balancear a través de instancias en múltiples zonas de disponibilidad de una región.
EC2 – Elastic Compute Cloud es un servidor virtual mediante el cual se puede crear capacidad de cálculo redimensionable en la nube.
S3 – Amazon Simple Storage Service (Amazon) hace que sea sencillo y práctico recopilar, almacenar y analizar datos independientemente de su formato y a una escala masiva.
RDS – Amazon Relational Database Service (Amazon RDS) es un servicio web que facilita la configuración, operación y escalabilidad de una o muchas bases de datos relacionales en la nube. Proporciona una capacidad rentable y redimensionable para bases de datos relacionales y cuenta con imágenes de los manejadores de bases de datos más utilizados, así como el propio (Aurora) y gestiona tareas comunes de administración de bases de datos.
Esta es una descripción muy breve de algunos de los servicios que AWS ofrece. Para obtener información más detallada, consulta la documentación de AWS.
Arquitectura LAMP de alta disponibilidad
Los datos valiosos nunca deben almacenarse sólo en el almacenamiento de la instancia sin las copias de seguridad adecuadas, la replicación o sin la capacidad de recuperar los datos. Amazon Elastic Block Store (EBS) ofrece volúmenes de almacenamiento persistentes fuera de las instalaciones que son de un orden de magnitud más duradero que el almacenamiento en las instalaciones. Los volúmenes de EBS se replican automáticamente dentro de una sola zona de disponibilidad. Para aumentar aún más la durabilidad, se pueden crear instantáneas (snapshots) puntuales para almacenar datos sobre volúmenes en Amazon S3, que luego se replican en varias zonas de disponibilidad. Mientras que los volúmenes de EBS están vinculados a una zona de disponibilidad específica, las instantáneas están vinculadas a la región. Mediante una instantánea, se pueden crear nuevos volúmenes de EBS en cualquiera de las zonas de disponibilidad de la misma región. Esta es una manera efectiva de tratar las fallas de disco u otros problemas a nivel de host, así como los problemas que afectan a una zona de disponibilidad. Las instantáneas son incrementales, por lo que es aconsejable conservar las instantáneas recientes.
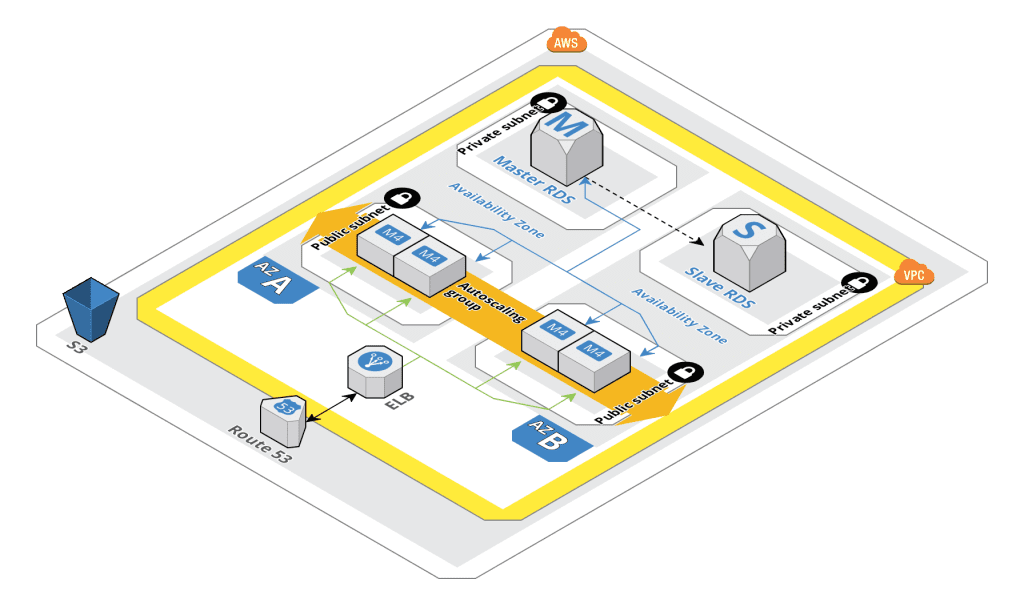
El diagrama anterior es un ejemplo de cómo se puede crear un servicio LAMP de alta disponibilidad utilizando los servicios en nube de AWS.
Route 53 recibe una petición del usuario, que es reenviada a un ELB, el ELB entonces reenvía esta petición a ambas zonas de disponibilidad y, por lo tanto, a cualquier servidor EC2 corriendo en esas zonas, entonces, en caso de que un AZ entero esté abajo el otro AZ todavía recibe la petición, para el servidor EC2 cuando recibe la petición comprueba la conectividad con el Master RDS, si no es accesible entonces el tráfico es desviado al RDS que está en latencia.
Para obtener alta disponibilidad, es necesario que el usuario tenga la misma información, independientemente del servidor o base de datos que proporcione el ELB. Es decir, tanto el servidor de EC2 como la base de datos deben tener la misma información que la del otro servidor y base de datos de EC2. De lo contrario, no será útil si el usuario obtiene una información diferente cada vez que las peticiones sean distribuidas a otro servidor por el ELB.
De esta manera la capa del servidor web, en este escenario, se asegura de que un error en una zona, no incapacite la operación del servicio porque:
- Los componentes redundantes para la misma tarea están en su lugar.
- El mecanismo que se encuentra encima de esta capa (el balanceador de carga) es capaz de detectar fallos en los componentes y adaptar su comportamiento para la recuperación oportuna.
Arquitectura LAMP de alta disponibilidad a prueba de fallos en ELB
Es difícil que el balanceador de carga falle, pero si se busca alta disponibilidad, se puede notar que el balanceador de carga puede ser un punto débil. Sin embargo, eliminar este punto único de fallo puede ser un reto; aunque puede configurar fácilmente un balanceador de carga adicional para lograr redundancia, no hay un punto obvio por encima de los balanceadores de carga para implementar la detección y recuperación de fallos. La redundancia por sí sola no puede garantizar una alta disponibilidad, debe existir un mecanismo para detectar fallos y tomar medidas cuando uno de los componentes del arreglo deje de estar disponible.
La detección y recuperación de fallas para sistemas redundantes puede implementarse utilizando un enfoque de arriba hacia abajo: la capa superior se convierte en la responsable de monitorear la capa inmediatamente inferior para detectar fallas. En el escenario de ejemplo anterior, el balanceador de carga es la capa superior. Si uno de los servidores web (capa inferior) no está disponible, el balanceador de carga dejará de redirigir las solicitudes para ese servidor específico.
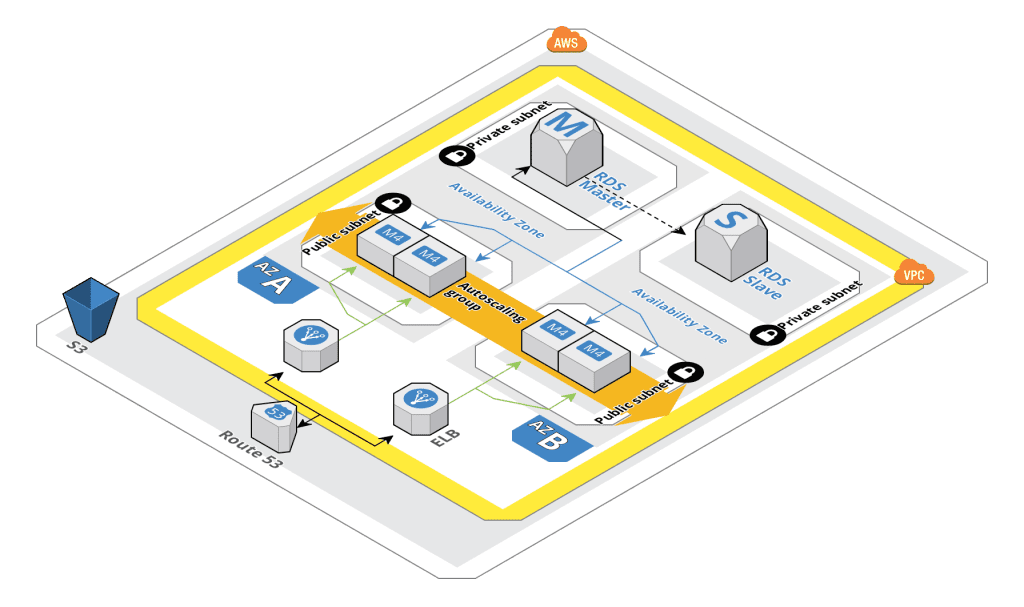
Con este escenario, es necesario un enfoque distribuido. Los nodos redundantes múltiples deben estar conectados entre sí como un clúster donde cada nodo debe ser igualmente capaz de detectar fallos y recuperarlos. Una solución más robusta y fiable es utilizar sistemas que permitan la redistribución flexible de direcciones IP, como las IP flotantes. La redistribución de direcciones IP bajo demanda elimina los problemas de propagación y almacenamiento en caché inherentes a los cambios de DNS al proporcionar una dirección IP estática que se puede volver a distribuir fácilmente cuando sea necesario. El nombre de dominio puede permanecer asociado a la misma dirección IP, mientras que la propia dirección IP se mueve entre servidores.
¿Qué componentes del sistema son necesarios para obtener alta disponibilidad?
Hay varios componentes que deben ser cuidadosamente tomados en consideración para implementar la alta disponibilidad en la práctica. Mucho más que una implementación de software, alta disponibilidad depende de factores como:
- Entorno: si todos sus servidores están ubicados en la misma área geográfica, una condición ambiental como un terremoto o una inundación puede hacer que todo el sistema se venga abajo. Tener servidores redundantes en diferentes centros de datos y áreas geográficas aumentará la fiabilidad.
- Hardware: los servidores de alta disponibilidad deben ser resistentes a los cortes de energía y a los fallos de hardware, incluidos los discos duros y las interfaces de red.
- Software: toda el arreglo de software, incluyendo el sistema operativo y la propia aplicación, debe estar preparada para manejar fallos inesperados que podrían requerir, por ejemplo, un reinicio del sistema.
- Datos: la pérdida de datos y la inconsistencia pueden deberse a varios factores, y no se limita a los fallos del disco duro. Los sistemas de alta disponibilidad deben tener en cuenta la seguridad de los datos en caso de fallo.
- Red: las interrupciones imprevistas de la red representan otro posible punto de fallo para los sistemas de alta disponibilidad. Es importante que exista una estrategia de red redundante para posibles fallos.
Conclusión
Obtener alta disponibilidad no sólo depende de una aplicación bien programada o de un sitio web resistente, también depende de toda la infraestructura que hay por debajo, tener un buen arquitecto y un equipo que te acompañe en caso de una falla en el sistema es fundamental para mantener tu negocio dentro de tus SLA.
¿Necesitas ayuda para rediseñar tu arquitectura? O ¿Planeas montar tu e-commerce a la nube?
Si contestaste sí a las preguntas anteriores estás de suerte, pronto tendremos un webinar en el que profesionales de Nubity y Amazon Web Services hablarán acerca de cómo obtener alta disponibilidad en tu sitio de comercio electrónico, ¡No te lo pierdas!
¡Regístrate ahora!*
*Cupo limitado
[:]